
In the fall of 2018, when I was just getting started in the world of text analysis, I signed up for a Cornell course Intro to Data Science where I attempted to get a grasp of the basics of data visualization, regression analysis, and categorization. As part of my final project, I turned to a data set of 130,000 wine reviews from Wine Enthusiast magazine, which was shared on Kaggle a while back. At the time, I only approached this topic as a simple demonstration of the skills I learned in the course. However, over time this project evolved into a different kind of endeavor, revealing strange trends that led me to question some of the assumptions I held about the regularity of aesthetic taste.
Recently, I had the opportunity to share some of this work with the podcast Microform – a project of the Humboldt-Universität zu Berlin. You can listen to recording here, along with the accompanying visualizations.
Consider the following short wine reviews, which you might find posted on little cards in your local wine store. At most, they are a few sentences long and are printed with a ‘score’ on a 100-point scale. Most of the time, these texts are relatively benign, but every once in a while you’ll find a few that really pack a lot of content into their limitations of form:
Ripe tangerine, peach, green apple and vanilla flavors combine with brisk, citrusy acidity in this wine. This wine saw a touch of neutral oak, which seems to have contributed a smoky toast character. It picks up complexities as it warms and airs, so don’t drink this too cold.[1] [Points: 87]
This ’06 Zin is as spicy and fruity as you could desire, with masses of currants, cocoa, orange peel, licorice and pepper. But the tannin-acid balance is great, giving it a wonderful structure. Best now for youthful exuberance.[2] [Points: 87]
The wine is a velvet glove in an iron fist. The smooth surface of ripe fruits and rich blackberry flavors, masks the dense tannins that will allow this very great wine to age for many, many years. The acidity and the rich fruit combine with the fine dusty tannins. The wine will surely not be ready to drink before 2027.[3] [Points: 96]
For six bucks you get a dry, rich, creamy Chardonnay with nice flavors of pineapples, pears, apples and smoky vanilla. This is a great price for a wine of this polished appeal.[4] [Points: 84]
In these examples, we see a wide range of short reviews (approximately 50 words each) covering all types of wines, and which are written by a wide variety of authors at the magazine.
In citing these texts under the rubric of the ‘review,’ these small forms exemplify an often-overlooked genre of writing that now dominates the world of professional wine tasting. Yet apart from its overt commercialization, the review has subtly reshaped the way the public sees and engages with the subjective experience of taste. In terms of its form, the reviews are stringently short in word count, calling to mind the unsurpassable word limit of a Tweet or the punctuating brevity of a news bulletin. Most interesting, however, is the text’s claim to communicate mastery of the wine’s flavor profile in a few words. In doing so, it seeks to grasp the wine’s essential elements and communicate an aspect of experience that is typically resistant to the simplifications of language. As professional sommeliers, the authors are highly trained and experienced in all aspects of wine and supposedly have developed a unique ability to identify distinguishing features of a particular wine that seem almost hidden to the average consumer. In this aspect, the goal of the review is precision – Capture all and only those subtleties of taste that give the wine its unique value. Waste no space on unnecessary thoughts or indistinct features.
Furthermore, these reviews are all accompanied by a particular point value that is assigned by the reviewer who writes the text. The point system is based on a 100-point scale, with 100 being the perfect wine, although in practice most wines do not receive fewer than 80 points. On the one hand, the advantage of this point system lies in its efficiency in presenting the judgments of critics to the marketplace: If a wine receives a high point value, the winemaker may use this review in marketing the product, and indeed one often sees these short blurbs posted on the shelf of the local wine shop. However, this use of points seems to belie the text’s attempt to capture the particularity of experience, as it gives a common rubric for which wines can be compared, sorted, organized, and ranked independently of the unique descriptors provided in the text. As you can see, the two 87-point wines mentioned earlier are hardly identical in terms of taste. The first review (above) emphasizes its acidic character; the second review contains a tannic-acid balance with “spicy” elements. Yet when both wines are assigned the same value, these nuances of the tasting experience are lost, and what remains is an abstract degree of quality that is not rooted in any particular empirical feature of the variety.
Nevertheless, while the score may seem to be in contrast to the text, the two are not entirely divorced from one another. After all, these values are not arbitrarily assigned but generated by the authors themselves to justify the opinions presented in the text or otherwise capture the meaning that they wish to express. Moreover, these scores are not based on a single, universally applicable set of criteria, but are loosely generated by the author’s own set of priorities – one author’s idea of the perfect, 100-point wine may be entirely different from that of another. In this sense, the scores are not always reductive simplifications of experience, but may occasionally present a concise representation that goes beyond the particularity of the text.
In taking these factors together, I am interested in looking at this ‘review’ as a short-form genre that offers unique tensions between description and quantification.
The contemporary form of the wine review can be traced back to the work of Robert Parker, founder of The Wine Advocate and widely considered to be the most influential wine critic in the western world. Beginning in the 1970s, Parker standardized the point-based model to counter what he perceived to be elitism and conflicts of interest in the wine industry. In his view, wine reviews lacked integrity and authenticity, making judgments based on reputation and other factors that are extraneous to the experience of the wine itself. In resisting the Continental decorum that glorified established wineries, Parker embodied a particular American brand of brute straightforwardness and individualism that was both foreign to the European wine community and yet instrumental to popularizing wine culture in the United States. His conception of the wine critic is one of intense courage in defending an independent viewpoint, and as he argues, the only opinions that truly matter of those of the consumers themselves. [Parker, Robert. Parker’s Wine Buyer’s Guide. 6th ed. New York: Simon & Schuster, 2002. Print.]
In this light, Parker sought to develop a system of writing in which wines could be compared on their empirical qualities alone and contextualized along common points of reference.
Yet this emphasis on democratizing wine has hardly diminished the significance of the reviewer in the industry as a whole. In proposing a 100-point system for wine reviews, the resulting ‘Parkerization’ of wine has resulted in a state of affairs in which newer, more unknown wines can be re-classified alongside older reputable brands. This may give critics like Parker enormous power in deciding the fate of any new wine that reaches the market. In fact, some recent statistical studies have suggested that an influential critic may have a significant impact on the price of a wine, and indeed there are a number of cases in which a winemaker has adjusted prices in response to a positive or negative review written by Mr. Parker alone. [Hay, Colin. “Globalisation and the Institutional Re-Embedding of Markets: The Political Economy of Price Formation in the Bordeaux En Primeur Market.” New Political Economy 12.2 (2007): 185–209. Web.] Given this increase in authority of influential wine critics, it seems evident that the numerical value of a review contributes some degree of persuasiveness and brings together the variety of textual responses into a unified system of comparison.
In recent years, the emergence of data science has led many researchers to explore questions of wine quality and prediction from a statistical perspective. In one popular data set, researchers gathered the chemical properties of thousands of wines (e.g. pH levels, sulphates, chlorides, etc.) along with ‘quality’ labels set by humans. [Asuncion, A. & Newman, D.J. (2007). UCI Machine Learning Repository [http://www.ics.uci.edu/~mlearn/MLRepository.html]. Irvine, CA: University of California, School of Information and Computer Science. http://mlr.cs.umass.edu/ml/machine-learning-databases/wine-quality/] Users would then apply machine learning techniques to generate models to predict the ‘quality’ of the wine on the basis of its chemical properties. For example, one user modeled wine data and determined the chemical properties that had the greatest influence on the human’s judgment: In this case, the ‘residual sugar’ was most positively correlated with quality, whereas ‘density’ was most negatively correlated with that outcome. As self-trained data scientists made use of this mass data, these models have become increasingly successful in predicting the human’s qualitative judgment on the basis of those empirical inputs. This therefore raises the possibility of a paradigm shift in the way we assess matters of taste. Unlike some earlier paradigms of aesthetic criticism, which emphasize the skill and education of the expert in uncovering underlying layers of the work, the new paradigm sees hidden regularities when one observes the accumulation of all aesthetic judgments in large numbers.
My own interest in this area of research began with the posting of the aforementioned wine review data set in which the user raised the possibility of predicting a wine on the basis of the words used in its description. Whereas most other data sets dealt primarily with numerical data, here was an example in which information extracted from texts could be combined with those numerical features to predict something entirely non-numerical. Moreover, looking at this question from the perspective of a literature scholar, I was intrigued by the possibility that statistical methods could demonstrate a correlation between our descriptions of our mental states (as formulated in the review) and the empirical reality of the wine’s identification. To me, this kind of study was hardly a trivial Fingerübung, but rather a significant development in the way we read small forms, giving us insight into new forms of knowledge that arise through a ‘distant reading’ perspective.
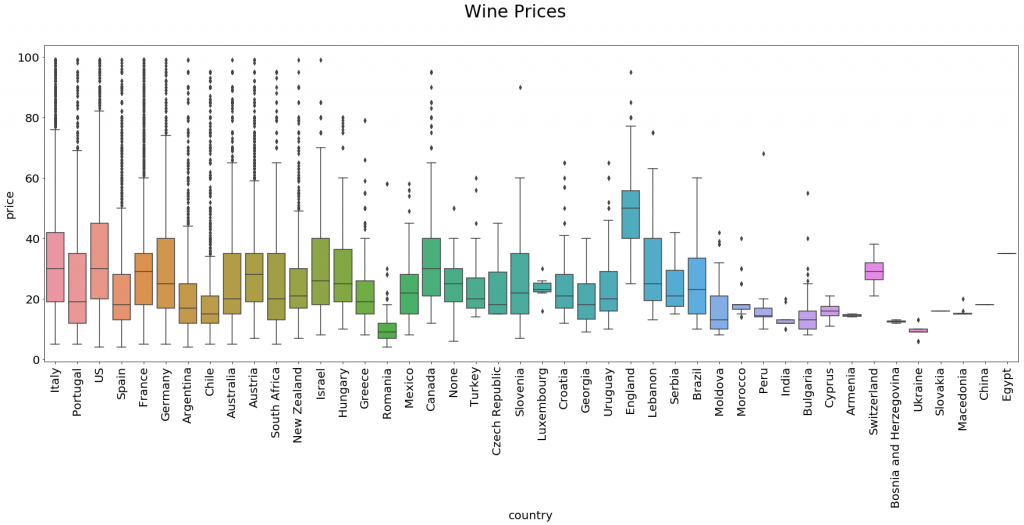
In examining the wine data set, a similar phenomenon emerges in which the contingency of experience in the review gives way toward lawfulness and even predictability at a large scale. When we read one of the reviews, it seems that the review embraces the particular experience of the wine as a singularity. However, when we compare these reviews on a larger scale, a number of interesting observations emerge. For example, consider the way the length of the reviews correlate with the score assigned by the critic:
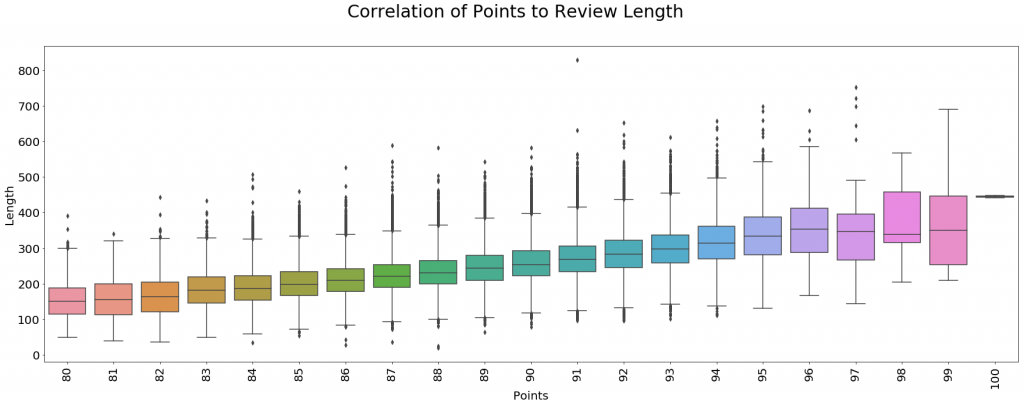
First, if we collect the lengths of each review (some being shorter than others), then we see a highly linear relationship between that feature and points. In other words, critics tend to write more words about wines that they like than those that they don’t. There could be a number of explanations for this finding, which could lead us back toward a close reading. On the one hand, critics could simply enjoy writing about delicious wines and are more willing to commit their time toward those reviews. Alternatively, we can also see a tendency of the critic’s language to mark differentiations in positive experiences that they otherwise would not with negative ones. A highly rated wine might be characterized by a number of analogous flavors that the critic wants to tease out from the experience, whereas the negative wine might contain a single flavor that overshadows the others [One 80-point review reads: “After the sulfur smell blows off, this wine remains tough in acids and tannins.”].
Another tool to measure the qualities of texts is ‘Textblob,’ [https://textblob.readthedocs.io/en/dev/ . The ‘sentiment’ scores range from -1 (most negative) to 1 (most positive) with 0 being neutral sentiment. The ‘subjectivity’ scores range from 0 (objective language) to 1 (entirely subjective language).] a natural language processing toolkit that can measure the sentiment and subjectivity of any text. The tool is based on a large corpus of words that are tagged with numerical values corresponding to their level of sentiment or subjectivity, as the case may be. For example, a word like ‘sunflower’ may be labelled with positive sentiment, while ‘pretty’ would indicate a high degree of subjectivity. This tool then takes a given text and assign it values by comparing the words in that text against those in the corpus on which it is trained. In the case of this data set, I used this tool to generate sentiment and subjectivity scores for each of the 130,000 reviews, which would offer a text-based numerical feature that could be used to compare against other numerical features, such as price or score.
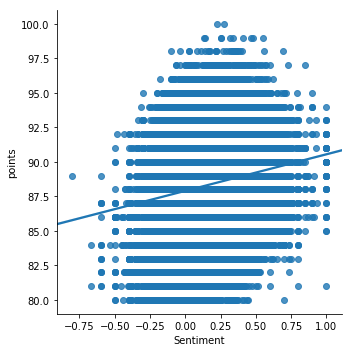
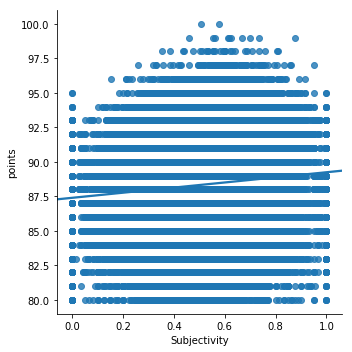
When we plot Textblob-generated data, we can see a certain correlation emerge between the computer-generated characteristics of the text and the numerical values assigned by the human. For example, as the sentiment of the texts increases from the most negative to the most positive, the reviewer’s score is also likely to increase from the average 80-range up to the more prestigious 90s. A similar trend is also evident in the measurements of subjectivity. The more often a text registers as highly subjective in its language, the average point value also rises.. Therefore, to some extent, the machine learning model can ‘read’ the texts in similar ways as humans do, meaning that the apparent sentiment of the texts corresponds to some degree to the author’s own assessment of that wine. To be sure, there is a large amount of variation, but as with any statistical analysis, there is a regularity that emerges on a large scale.
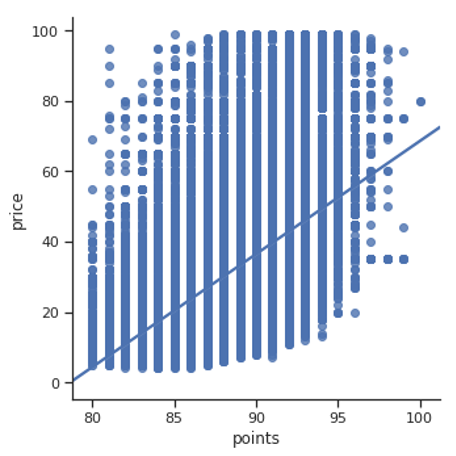
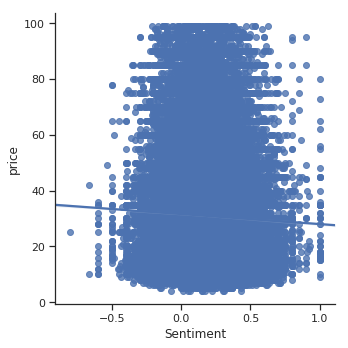
While these computational tools may succeed in ‘reading’ the sentiments of the writers, this method does not always produce intuitive results. If we compare the correlations associated with price, for example, we appear to confront a paradoxical distinction between the computer’s reading and the actual human-generated score. Here it seems critics tend to assign higher points to wines that have a higher price, despite these reviews being blind tastings that do not reveal the product’s market value. If this is accurate, then it seems the critics may be exposed to certain biases leading them to rank pricier wines more highly than others. However, the ‘sentiment’ score shows little correlation with price, despite the sentiment and points showing a positive correlation to each other. To me, this result shows an interesting gap between the sentiment of the text and the score. While the critic may be willing to write favorably about a cheap wine, they may ultimately assign a score that corresponds more closely to its reputation or market value.
Thesis
When accumulated into large numbers, certain forms of small texts often show similar kinds of statistical regularity as other numerical points of information. This regularity seems to hold true not just for matters of empirical reality (the number of births, deaths, crimes, etc.), but also for matters of aesthetic taste. In what I’ve described above, I have given only the most surprising regularities and trends that occur for writing about wines. However, there is no reason to assume that this law of large numbers is limited only to commercial industries but could perhaps occur in many other contexts of short form writing, including literary ones. In this data-driven mode of distant reading, it is increasingly essential for the literary scholar to understand and interpret ‘big data’ of textual information and use those insights to return to the close reading with new questions and hypotheses.
[1] #61995. “Epiphany 2011 Camp Four Vineyard Grenache Blanc (Santa Barbara County).” Sentiment: -0.4, Subjectivity: 0.65.
[2] #63202. “Courtney Benham 2006 Zinfandel (Dry Creek Valley).” Sentiment: 0.933, Subjectivity: 0.683.
[3] #15840. “Château Pétrus 2014 Pomerol.” Sentiment: 0.34, Subjectivity: 0.619 ($2500)
[4] #61694. “Leaping Horse 2008 Chardonnay (California).” Sentiment: 0.427, Subjectivity: 0.775 ($6)